Training State of the Art Vulnerability Discovery Agents through Reinforcement Learning
Our mission at depthfirst is to build General Security Intelligence to secure the world’s software. We believe achieving this requires optimizing the entire stack, from the product to the agents and models, for two primary capabilities: the detection and verification of vulnerabilities.
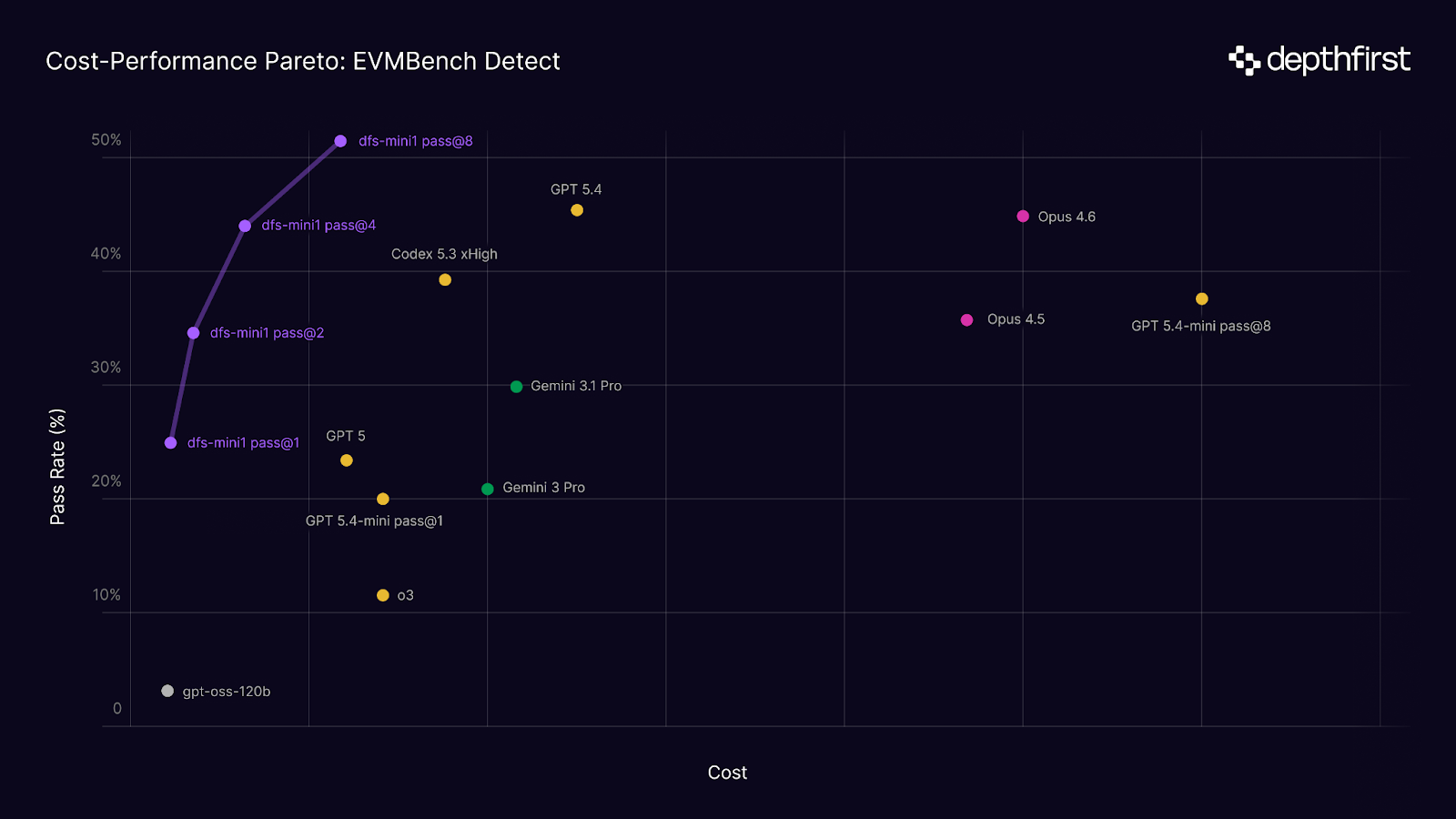
In this post, we’re sharing our progress in building specialized security models and domain-specific RL environments. To start, we target OpenAI’s EVMBench Detect, a benchmark that evaluates an agent’s recall of high-severity smart contract vulnerabilities that can result in irreversible loss of funds. We introduce our new agent, dfs-mini1, which we co-trained with our security-optimized harness via Reinforcement Learning to detect these threats. It achieves Pareto optimality on the benchmark and state of the art performance at pass@8.
Training
dfs-mini1 is post-trained via reinforcement learning with a continuous reward signal based on overall detection coverage. We built infrastructure to spin up and run thousands of sandbox environments on Kubernetes, where an agent is given a repository to audit and tasked with identifying vulnerabilities using only the shell provided in the container.
Environments
Training environments were sourced from historical smart contract audits with zero overlap with EVMBench to prevent data contamination. These environments are also characteristically different from the evaluation set, averaging 50% more sLOC in scope, spanning Solidity, Rust, Cairo, and Vyper, and drawn from multiple auditing platforms. EVMBench, by contrast, is sourced exclusively from Code4rena and limited to Solidity.
EVMBench Detect grades purely on recall, or the fraction of ground truth vulnerabilities recovered by the agent, with no penalty for false positives. This means pass@k can be computed by simply taking the union of detections across rollouts, without requiring an oracle or majority vote to select among them.

Context Management
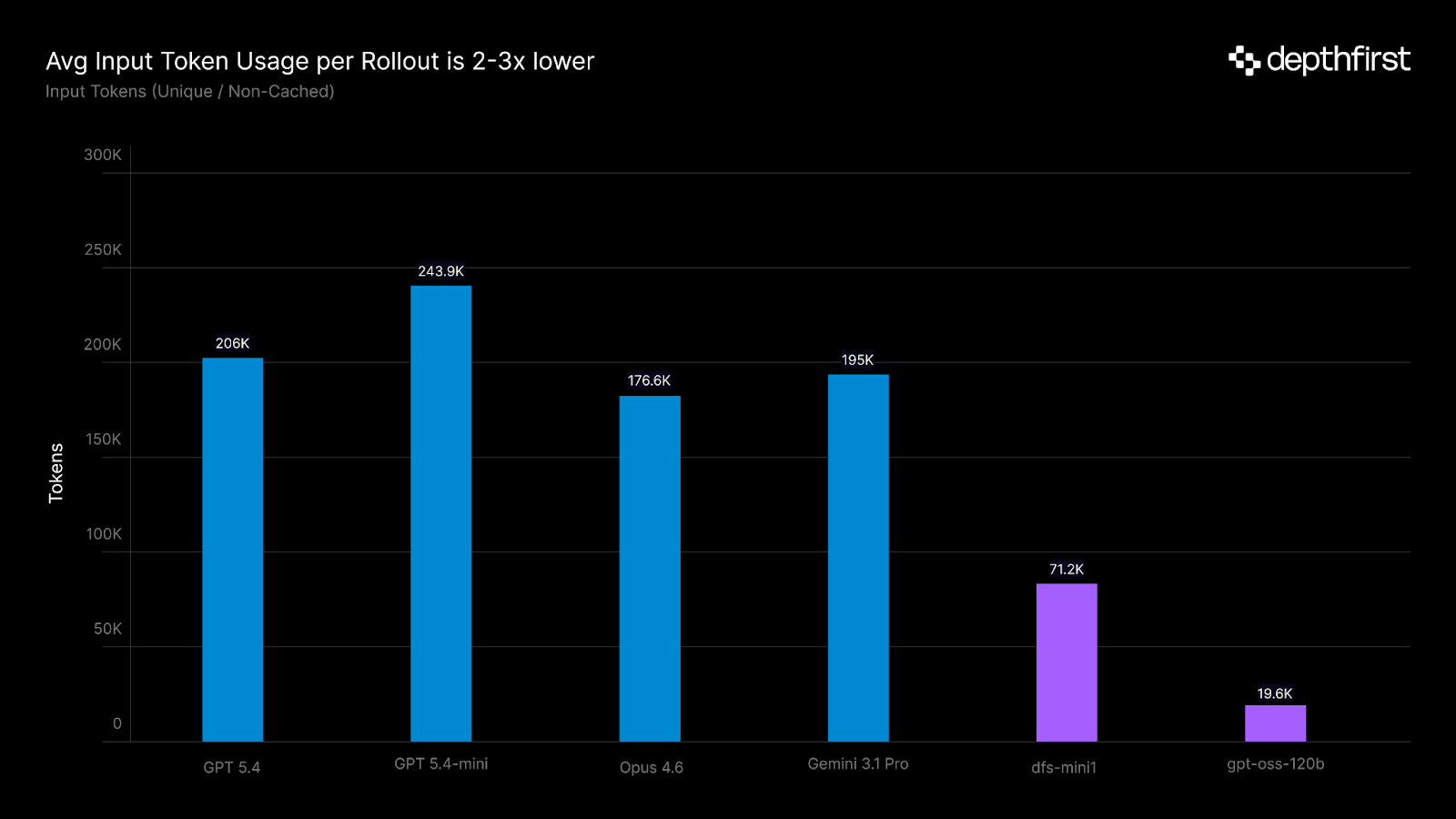
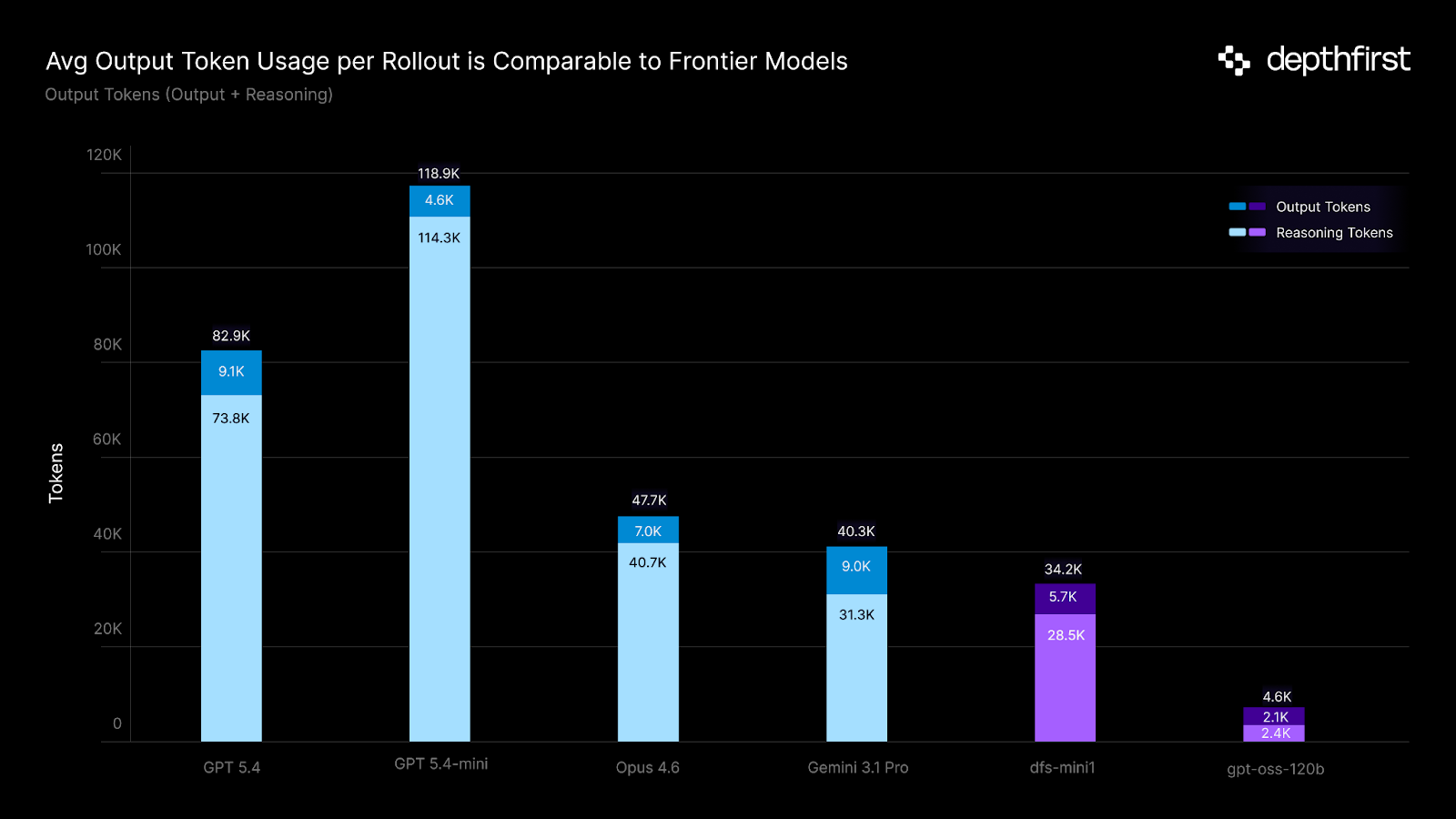
A key constraint of our post-training setup is a restricted 32k context window, well below what the base model natively supports. For agents operating on multi-turn, long-horizon tasks like codebase auditing, this makes efficient context usage essential. As real codebases can easily reach millions of lines of code, we decided to train with summarization-based context compaction strategies motivated by recent publications (ReSUM, SUPO). In this setup, an agent’s trajectory is periodically compressed by training the same policy to summarize its current state along the MDP.
We observed several notable changes between the base model and the post-trained checkpoint as we scaled training compute. dfs-mini1 learned to utilize more turns and trigger more frequent compaction events per rollout; furthermore, the average token length of each summary decreased as the model learned to more efficiently compress stateful information.
Our results suggest that a restricted context window may not be as limiting as one might initially expect. A growing body of research has shown that language model reasoning degrades as input context grows, even when relevant information is present. In this setup, we keep our model operating in the regime where it reasons best and is forced to attend to only the most task-relevant information.
Tools
Context was not the only dimension where constraints proved beneficial. A behavior we noticed was the agent attempting to install static analysis tools like Slither. We found that this consistently led the agent to tunnel-vision on tool outputs that almost always consisted of false positives, so we decided to explicitly discourage this during training.
More broadly, this reinforced our choice to expose only low-level primitives (a shell tool) rather than higher-level specialized tools. Frameworks like Slither impose a fixed detection methodology that an agent might anchor on, collapsing the strategy space prematurely during training. On the other hand, a shell tool forces an agent to compose its own detection approaches from the ground up, enabling potentially more creative ways to discover vulnerabilities.
The Cost-Performance Pareto
dfs-mini1, built on gpt-oss-120b (an MoE model priced at $0.15/$0.60 per 1M input/output tokens), achieves Pareto optimality on cost versus performance when total token expenditure across rollouts is accounted for. At pass@8, it exceeds all evaluated frontier model detection at 10-30x lower total cost, driven by shorter trajectories and lower per-token pricing of the underlying model.
Agent Generalization
An exciting result we observed is that improvements from training on smart contract vulnerability detection transfer meaningfully to generic detection tasks. On Deep Vulnerable Hard, an internal benchmark of vulnerability discovery detection tasks derived from historical CVEs spanning various vulnerability classes and programming languages, dfs-mini1 improves both pass@1 and pass@3 performance considerably compared to its untrained counterpart.
Notably, these environments test our agents across a multi-component harness with tools, prompts, and codebases dfs-mini1 was never exposed to during training. The vulnerability classes also differ significantly mechanically: smart contract flaws originate from on-chain state & economic logic, while traditional web vulnerabilities like IDOR stem from failures in input validation and trust boundaries. Both tasks, however, ultimately involve the same reasoning of tracing how untrusted state flows through a system & identifying where checks are missing. Our qualitative analysis of trajectories found the model exhibiting these deeper reasoning patterns rather than memorizing surface-level signatures.
Limitations & Future Directions
One artifact of RL training is that dfs-mini1 learned to report significantly more vulnerabilities per task. We noticed that this scaled consistently with training compute. A key challenge during the optimization process is balancing recall and precision, as focusing primarily on recall leads to a higher number of false positives that eventually need to be filtered out.
An active area of research for us is to shape our recipe to jointly optimize for precision and recall. Training agents to programmatically verify discovered vulnerabilities through end-to-end exploitation is a natural next step on our roadmap. Detection and verification are fundamentally linked as exploitation forces the model to prove a detected vulnerability is real, not just plausible; so training a single policy on both tasks may offer a path to reducing false positives. The generalization we observed suggests a clear scaling path: more training compute, more diverse vulnerability tasks, and larger base models should further strengthen the transferable reasoning patterns we are already seeing.
This research is a step toward proving that specialized, post-trained agents can compete with frontier models and deliver meaningfully better vulnerability detection per dollar spent.